Overfitting là một hiện tượng xảy ra khi mô hình học máy phù hợp với tập dữ liệu kiểm tra mà không phù hợp với tập thực tế, nó thường xảy ra ở các mô hình phức tạp (complex models), như deep neural networks.
Regularisation là một quá trình để ngăn chặn họăc giảm thiều overfitting. Ở đây, chúng ta tập trung vào hai chuẩn là L1 và L2 regularisation.
Đã có khá nhiều giải thích trên mạng, nhưng thành thật mà nói có vẻ khi bạn đọc bài viết này thì những bài viết đó đã quá khó hiểu với bạn, vì thế, bài viết này, chúng ta cùng tìm hiểu rõ tại sao chuẩn L1 và L2 lại được dùng để tránh hiện tượng overfitting bằng cách mô tả lại quá trình Gradient Denscent, tối ưu hàm loss của model.
Bắt đầu nào.
0. L1, L2 là gì ?
L1, L2 regularisation hay còn được gọi là L1, L2 norm của vector w, dưới đây là công thức:
1-norm (L1 norm)
2-norm (L2 norm hoặc Euclidean norm)
.Trong hồi quy tuyến tính (linear regression), kèm với L1 còn được gọi là lasso regression, kèm L2 được gọi là ridge regression, (mình không thể dịch hai loại hồi quy này ra tiếng Việt mà dễ hiểu hơn).
Đầu tiên, hãy nói về mô hình hồi quy tuyến tính ban đầu:
Hàm loss function ban đầu, L1, L2:
Loss function ban đầu
Loss function với L1 regularisation
Loss function với L2 regularisation
Có thể thấy, regularisation ràng buộc hàm loss lại, ngoài việc hàm loss luôn phải giảm trong quá trình training, tức là tối thiểu hóa khoảng cách sai số giữa giá trị dự đoán và giá trị thật, nó còn phải "tuân thủ" chuẩn L1, hoặc L2 đã đề ra.
Trước khi để hiểu tại sao khi áp dụng L1, L2 vào lại hiệu quả hơn, ta cùng tìm hiểu về model.
1. Model
Đây là công thức tổng quát của mô hình hồi quy tuyến tính, w là trọng lượng, b là hệ số thêm vào. Hãy tưởng tượng nó là một phương trình x,y tầm thường, nếu không có b thì nó sẽ luôn luôn đi qua gốc tọa độ, điều đó làm giảm tính linh hoạt của mô hình.
Thực tế, mô hình hồi quy tuyến tính không dễ gì bị hiện tượng overfiting, các mô hình học sâu dễ bị như thế bởi tính phức tạp của mô hình.
2. Loss function
Chúng ta định nghĩa hàm mất mất được tính theo công thức bình phương lỗi (squared error), nơi mà lỗi được định nghĩa là khoảng cách sai số giữa giá trị dự đoán (y mũ) và giá trị thật sự y.
Dựa theo hàm mất mát ở trên, áp dụng chuẩn L1 vào nó sẽ trông như sau:
Hệ số lamda là hệ số tuỳ chỉnh, lưu ý rằng, |w| không được bằng 0 theo c
Tương tự, đây là loss function áp dụng chuẩn L2:
3. Gradient Descent
Giờ chúng ta sẽ áp dụng Gradient Descent để tối ưu hóa 3 hàm loss ở trên xuống mức tối thiểu bằng cách cập nhật lại hệ số w và b sau mỗi lần lặp.
Với n là hệ số learning rate, đây là cách cập nhật trọng số w cho 3 hàm loss phía trên:
L:
L1:
L2:
Nếu bạn không thể hiểu được 3 mục ở trên, hãy xem lại thật kỹ, đó là quá trình cập nhật lại trọng số w của model bằng backpropagation, hiểu đơn giản, là dùng đạo hàm qua quy tắc chain rule để cập nhật lại trọng số (quá trình truyền ngược, truyền xuôi chính là quá trình ra được giá trị hàm loss), mình sẽ viết một bài viết khác để giải thích vấn đề này.
4. Làm thế nào để ngăn chặn overfitting ?
Từ đây trở đi, hãy coi hệ số learning rate n=1, và H = 2x(wx +b -y) để dễ hiểu hơn.
L:
L1:
L2:
Quan sát cập nhật trọng số w khi có chuẩn L1 và L2 và khi không có.
Hãy cùng nhìn vào phương trình (0), tính toán w-H giúp ta có hệ số w mới, coi đó là nguyên nhân dẫn đến hiện tượng overfitting thì phương trình 1.1, 1.2 và 2 sẽ làm giảm hiện tương overfitting vì giờ đây chúng ta có lamda, chuyển từ quan tâm w sang quan tâm hệ số lamda này.
Giả sử một model bị overfitting có nghĩa là chúng ta có hệ số w hoàn hảo cho model. "Hoàn hảo" nghĩa là nếu chúng ta cho tập thử nghiệm (x) vào model, thì hàm trả về y mũ luôn luôn, rất gần với giá trị thật y. Chắc chắn, nó là một điều tốt, nhưng nó không hoàn hảo. Tại sao ?
Bởi vì điều đó đi chỉ có ý nghĩa trên tập mà chúng ta đã đào tạo, hãy nhìn vào tấm hình đầu tiên của bài viết, nó làm cho mô hình mất khả năng dự đoán trên các tập dữ liệu khác, vì vậy, chúng ta làm giảm sự hoàn hảo của việc cập nhật các hệ số ấy, với hi vọng làm giảm khoảng cách giữa tập dự đoán và tập dữ liệu thật, hay nói cách khác, điều chúng ta làm là phạt các model với hệ số lamda.
Lưu ý rằng H định nghĩa ở đây phụ thuộc vào model (w,b) và dữ liệu (x,y), khi thêm hệ số lamda vào, nó độc lập với model và dữ liệu, do đó, chúng ta sẽ tránh được overfitting nếu đặt một giá trị lamda thích hợp.
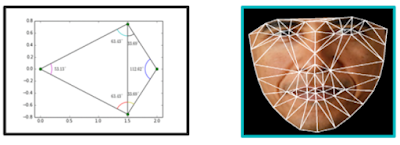
This post is pending Intro: faceswap & deepfake Face swap refers to an activity in which a person's face is swapped with the face of another person. Deepface = deeplearning + fake. Deepfake is an advanced technology, but 96% ò Deepfakes videos have triolous content. Deepfake also targets political purposes, fraud and market manipulation. Traditional swap face - using opencv-dlib Facial landmark Detection Facial landmarks are used to localize and represent salient regions of the face. The pre-trained facial landmark detector inside the dlib library is used to estimate the location of 68(x,y)-coordinates that map to facial structures on the face. Each frame of the animation shows a Delaunay trianulation of the four points. Halfway through, the trianglulating edge flips showing that the Delaunay trianglulation maximizes the minimum angle, not the edge-length of the triangles. The final steps of face alignment to to consider corresponding triangles between the source fac...

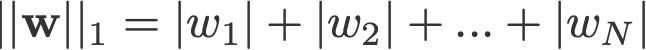

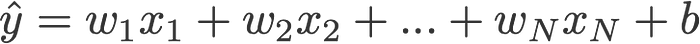
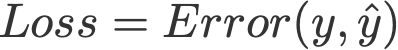
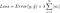
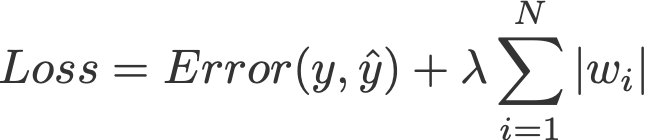

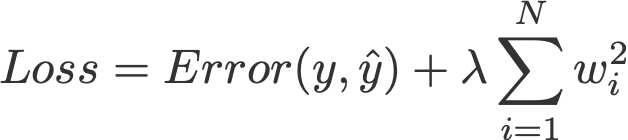

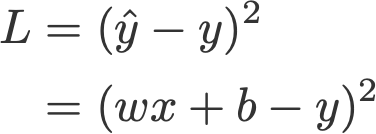
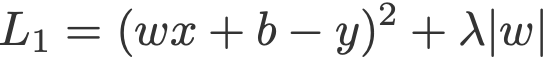
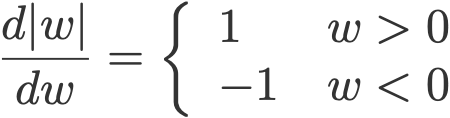
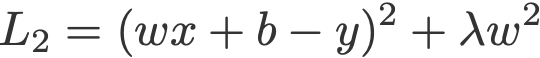
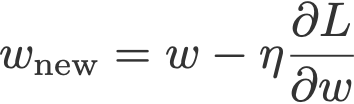

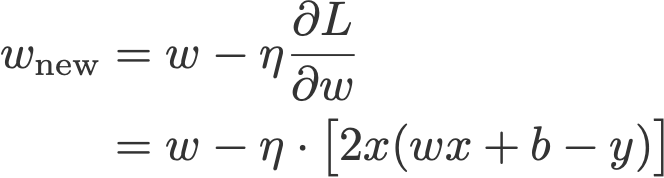

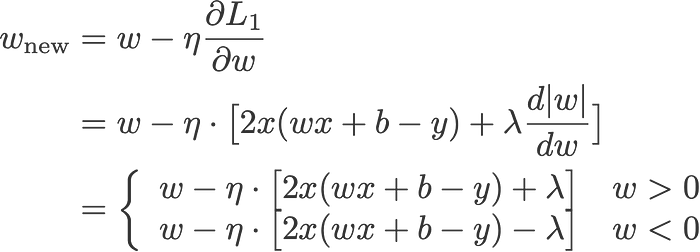

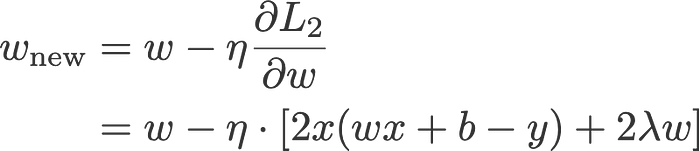


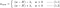
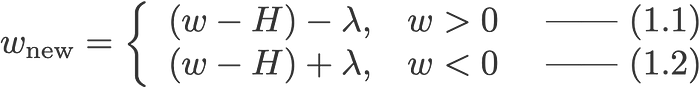


Nhận xét
Đăng nhận xét